- "1000 sites * 20 services * 200 VOs * 10 roles/groups = 40M metadata"
- "100k CPUs * 10 jobs per day * 10 queries per job = 10M queries per day, 115 queries per second."
- Publishing one service adds 138 RDF statements to the triple store, which consumes up about 25 KB of memory. Then each triple uses 181 bytes. Each metadata has at least 3 triples: (entity, hasMetadata, metadata), (metadata, hasMetadataType, type), (metadata, hasMetadataValue, value). Thus 4M metadata uses 181 * 3 * 4M = 2.1GB.
Friday, December 15, 2006
Use Numbers
To argue, try to use statements with numbers, like
Wednesday, December 06, 2006

Tuesday, December 05, 2006
Create A User Community to Improve Our Open Source Software
Why?
- Create impact. Open source software's value relies on its usage.
- Get feedback, which could be good ideas for the future work.
- Create a well organized website, easy downloads, a bugzilla system, etc. Twiki and Sourceforge are very helpful in this sense.
- Well answer questions by email.
- Create a user list, which includes the project name, url, contacts, etc.
Monday, December 04, 2006
My New Laptop
 Today I got a new laptop, a SONY VAIO, which has
Today I got a new laptop, a SONY VAIO, which has- Intel® Core™ 2 Duo T7200 Processor 2.0GHz
- 2GB, 100GB HDD & DVD/RW Super Multi DL Drive
- 13.3" WXGA TFT Display, Bluetooth & FREE T-Mobile WAN Card
- ... ...
- And a fingerprint reader! So that I am able to log in Windows by using my fingerprint. Cool!
Sunday, December 03, 2006
学什么专业?挣多少钱?——美国各级毕业生2006薪水调查
摘自八阕。
<CopiedContent>
八阕】美国大学与雇主协会,每年按4个季度分别发布新毕业的大学生、 硕士和博士研究生的薪水调查报告,这报告共涉及80个学士专业,40个硕士专业,23个博士专业。冬、春、夏三季发布的数据是各季度的数据,秋季版发布的 是去年8月31日到今年9月1日为止的整个学年数据。以下列出的是该协会最新公布的美国博士和硕士毕业生2006年秋季薪水调查报告。
我的评论:
"Indeed, it was outsiders—those with expertise at the periphery of a problem's field—who were most likely to find answers and do so quickly."
八阕】美国大学与雇主协会,每年按4个季度分别发布新毕业的大学生、 硕士和博士研究生的薪水调查报告,这报告共涉及80个学士专业,40个硕士专业,23个博士专业。冬、春、夏三季发布的数据是各季度的数据,秋季版发布的 是去年8月31日到今年9月1日为止的整个学年数据。以下列出的是该协会最新公布的美国博士和硕士毕业生2006年秋季薪水调查报告。
美国博士毕业生2006年薪水最高的几种专业:
1、商业管理(Business Administration/Management):$81,438
2、电气/电子与通信工程(Electrical/Electronics & Communications Engineering): $81,297
3、冶金工程(含陶瓷科学与工程)(Metallurgical Engineering ):$80,667
4、计算机科学(Computer Sciences):$76,630
5、化学工程(Chemical Engineering):$75,659
6、计算机工程(Computer Engineering):$74,750
7、工业/制造工程(Industrial/Manufacturing Engineering):$73,292
8、物理(Physics):$72,357
如果这些工程师没有升迁到高层管理,做到退休一般年薪不会超过$150,000
美国博士毕业生2006年薪水最低的几种专业:
1、心理学(Psychology):$49,374
2、人文科学(Humanities):$48,938
3、社会科学(Social Sciences):$48,487
4、生物/生命科学(Biological Sciences/Life Sciences):$43,916
5、英语语言与文学(English Language & Literature/Letters ):$41,405
美国硕士毕业生2006年薪水最高的10种专业:
01、计算机科学(Computer Sciences):$71,165
02、石油工程(Petroleum Engineering):$68,833
03、电气/电子与通信工程(Electrical/Electronics & Communications Engineering):$66,687
04、计算机工程(Computer Engineering):$66,545
05、地质及相关科学(Geological & Related Sciences):$64,111
06、材料科学(Materials Sciences):$63,500
07、航天/航空/宇航工程(Aerospace/Aeronautical/Astronautical Engineering):$62,811
08、工业/制造工程(Industrial/Manufacturing Engineering ):$61,273
09、机械工程(Mechanical Engineering):$61,234
10、化学工程(Chemical Engineering):$59,008
如果这些工程师没有升迁到高层管理,做到退休一般年薪不会超过$120,000
2004年美国律师的年薪平均为:$94,930
最低年薪:$64,620,最高年薪: $143,620
在公司和企业管理层谋职(Management of companies and enterprises):$126,250
在联邦政府谋职(Federal Government):$108,090
在法律机构谋职(Legal services):$99,580
在地方政府谋职(Local government):$73,410
在州政府谋职(State government):$70,280
2004年美国各科医生的年薪:
麻醉科(Anesthesiology):$306,964
外科、普通外科(Surgery, general):$255,438
妇产科(Obstetrics/Gynecology:$233,061
内科(Internal medicine):$155,530
小儿/青少年科(Pediatrics/Adolescent medicine):$152,690
精神科(Psychiatry):$163,144
家庭全科(Family Practice):$150,267
联邦人口普查局2006年11月还发表了一项调查数据“2004年美国学历与平均年薪”:
高中以下学历平均年薪:$19,169
高中毕业平均年薪: $28,645
大学毕业平均年薪: $51,554
硕士以上学位平均年薪:$78,093
从以上各项的调查报告看来,华人根深蒂固的教育观念“学好数理化,走遍天下都不怕”,似乎真的放之四海而皆准了。并且,华人父母努力说服自己的子女当律师和医生也是有根有据的。当然,学历越高收入越多的说法更是真理。
</CopiedContent>我的评论:
- 选择专业前先要做好各个专业的benchmark, 什么专业工资最高。看来benchmark真是无时无地不重要。
- 计算机科学博士起薪只比计算机科学硕士高7.7%。虽然理论上博士比硕士有更好的成长空间,究竟读不读博士还是要慎重考虑。
- 医生收入压倒性的高,远高于其他专业,甚至包括律师。还是学医收入高。
- 读书有用啊。读书越多,收入越高。
"Indeed, it was outsiders—those with expertise at the periphery of a problem's field—who were most likely to find answers and do so quickly."
Friday, December 01, 2006
Java I/O
This presentation gives a good overview of Java I/O, from which I have learned:
- FileInputStream/FileOutputStream: for sequential I/O and simple to buffer
- RandomAccessFile: for full random-access
- FileChannel: adds support for NIO byte buffers
- MappedByteBuffer: for memory-mapped I/O
- Buffering: for instance, use BufferedOutputStream for buffering FileOutputstream
- Forcing I/O, e.g. flush() or FileChannel.force(), equals to the "fsync" system call
- No direct I/O in Java
Thursday, November 30, 2006
Google File System
The Google File System is a scalable distributed file system for large distributed data-intensive applications, being used within Google. The paper, published in the 19th ACM Symposium on Operating Systems Principles, is a well written computer engineering paper. System builders should read it.
Quoted from its conclusion:
"We started by reexamining traditional file system assumptions in light of our current and anticipated application workloads and technological environment. Our observations have led to radically different points in the design space. We treat component failures as the norm rather than the exception, optimize for huge files that are mostly appended to (perhaps concurrently) and then read (usually sequentially), and both extend and relax the standard file system interface to improve the overall system."
Lesson learnt:
Lesson learnt:
Lesson learnt:
This elegance makes perfect sense in the domain of system design. May we say in system design, elegance is not a dispensible luxury, but a matter of life and death.
Quoted from its conclusion:
"We started by reexamining traditional file system assumptions in light of our current and anticipated application workloads and technological environment. Our observations have led to radically different points in the design space. We treat component failures as the norm rather than the exception, optimize for huge files that are mostly appended to (perhaps concurrently) and then read (usually sequentially), and both extend and relax the standard file system interface to improve the overall system."
Lesson learnt:
- Application driven.
- Base on the technological environment. Base on the facts of performance characteristics. Performance benchmark is the foundation for system design.
- Application/file system (or OS, or underlying infrastructure, etc.) co-design.
- Optimize for what should be optimized.
Lesson learnt:
- Reliability is a must for any system. System must work. Never forget reliability, persistence, fault tolerance during system design.
Lesson learnt:
- Down to earth.
- ...I had already come to the conclusion that in the practise of computing, where we have so much latitude for making a mess of it, mathematical elegance is not a dispensible luxury, but a matter of life and death. - Edsger Wybe Dijkstra ["My hopes of computing science" (EWD 709)]
This elegance makes perfect sense in the domain of system design. May we say in system design, elegance is not a dispensible luxury, but a matter of life and death.
Friday, November 17, 2006

Thursday, November 16, 2006
A Very Interesting Story
Copied from Ian Foster's blog.
<CopiedContent>
Hadoop on EC2
Here's something neat (and details here).
Hadoop, an open source clone of Google FS and MapReduce, can be run on top of Amazon EC2, a hosting service that allows leasing servers on an hourly basis.
As Greg Linden goes on to say:
Developers may now be able to rapidly bring up hundreds of servers, run a massive parallel computation on them using Hadoop's MapReduce implementation, and then shut down all the instances, all with low effort and at low cost. Very cool.
My colleague Tim Freeman points out that you can run those same VMs on your own resources using the Globus Workspace service.
</CopiedContent>
I got a feeling that parallel computing becomes more and more available, and has better and better programmability.
Provenance of Life
We are moving. Our current landlord claims the carpet is "new". Although it does not look like a new one at all, and I remember it was not very clean when I moved in one year ago, we do not have any evidence to support our point. The landlord also blames us that we did not report problems to them promptly. Having consulted the university accommodation officer, we now learn that we had better write to them and keep a photocopy of the letter.
The evidence matters. The evidence could be pictures, receipts, letters, or anything concrete, not transient, but retrievable. Furthermore, the evidences should not be isolated. They should be logically linked together, and finally lead to some conclusion. Put it in another way, when we see an event in the life, we would like to "see" the complete process that leads to this event. By "see" we really mean to reconstruct it in a convincible way.
My boss is investigating a "provenance" project, which defines "the provenance of a piece of data is the process that led to that piece of data". The aim of the project is to "to conceive a computer-based representation of provenance that allows us to perform useful analysis and reasoning ...".
I argue we also need provenance support in our lives. Important facts should be documented in a retrievable and searchable way, for instance, in a computer-based way. We should keep recording provenance of life.
Google advocates searching instead of organizing. Ideally, as long as we record the provenance of life in our computer or on the internet, there should be a way to query and retrieve it.
I am interested in all techniques to improve productivity. It is great that some software could help to record the provenance of life an query over it, which will definitely improve our productivity of life.
The evidence matters. The evidence could be pictures, receipts, letters, or anything concrete, not transient, but retrievable. Furthermore, the evidences should not be isolated. They should be logically linked together, and finally lead to some conclusion. Put it in another way, when we see an event in the life, we would like to "see" the complete process that leads to this event. By "see" we really mean to reconstruct it in a convincible way.
My boss is investigating a "provenance" project, which defines "the provenance of a piece of data is the process that led to that piece of data". The aim of the project is to "to conceive a computer-based representation of provenance that allows us to perform useful analysis and reasoning ...".
I argue we also need provenance support in our lives. Important facts should be documented in a retrievable and searchable way, for instance, in a computer-based way. We should keep recording provenance of life.
Google advocates searching instead of organizing. Ideally, as long as we record the provenance of life in our computer or on the internet, there should be a way to query and retrieve it.
I am interested in all techniques to improve productivity. It is great that some software could help to record the provenance of life an query over it, which will definitely improve our productivity of life.
Saturday, November 11, 2006

Wednesday, November 08, 2006
The Outcome of MPT
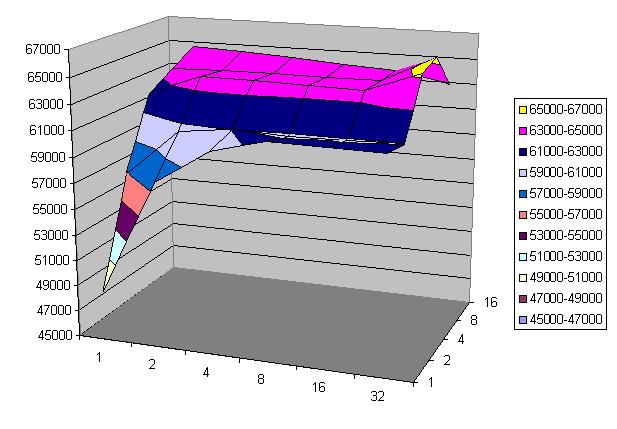 Here is a visualized outcome of MPT. The x-axis is the number of processors used in the throuthput test (1 - 32). The y-axis is the number of threads per processor (1 - 16). The z-axis is the measured throughput. More precisely, it is the number of service discovery (by name) requests served in 30 minutes when there are 5000 service descriptions registered in GRIMOIRES. When 32 processors and 16 threads per processor are used, GRIMOIRES can serve 62,877 service discovery requests in 30 minutes , i.e., 34.9 per second. Each request costs 28.6 milliseconds.
Here is a visualized outcome of MPT. The x-axis is the number of processors used in the throuthput test (1 - 32). The y-axis is the number of threads per processor (1 - 16). The z-axis is the measured throughput. More precisely, it is the number of service discovery (by name) requests served in 30 minutes when there are 5000 service descriptions registered in GRIMOIRES. When 32 processors and 16 threads per processor are used, GRIMOIRES can serve 62,877 service discovery requests in 30 minutes , i.e., 34.9 per second. Each request costs 28.6 milliseconds.
Tuesday, November 07, 2006
旅游大计
 星期六一早起床, 阳光明媚, 万物复苏. 乘机定下今后N年的旅游大计. 以求心中有数, 目标明确.
星期六一早起床, 阳光明媚, 万物复苏. 乘机定下今后N年的旅游大计. 以求心中有数, 目标明确.这里我来谈三点.
(一) 回顾过去, 成绩很大.
香港, 东方之珠, 生活5年, 非常好;
倫敦, 逝去帝国的首都, 非常好;
巴黎, 文化艺术之都, 非常好;
瑞士, 美丽的高山, 湖泊, 非常好;
芝家哥, the mile of magnificence, 不错;
加拿大BC, 温哥华, 维多利亚, 不错, 从温哥华到维多利亚的水路很美;
洛山基, 听说治安很差, 硬是没敢进downtown;
胜地呀哥, 还是不错的, 还看到了航母.
(二) 面对现实, 压力很大.
这里又要谈两点, 一如何在时间上创造机会, 二是如何在经济上开源节流. 以后有时间再版详细谈.
(三) 展望将来, 希望很大.
埃及, 非常想去看看古埃及的伟大;
日本, 又爱又恨, 要去走走;
台湾, 另类中国, 要去看看;
纽约, 要去;
拉丝围家四, 要去;
欧洲, 那是要经常过去看看的, 意大利, 西班牙, 德国, 北欧, ..., 法国和瑞士也要再去;
西藏的债也是要还的;
非洲, 南美, 大洋洲, 有机会都要去踩上几个脚印.
The Reasons to Have a Blog
According to Wikipedia, the term "blog" is a contraction of "web log". From its original name, blog can be inferred to have two characteristics that correspond to the two purposes for me to blog.
- Blog is a log that is organized as a chronicle. I can use blog to track events in my life and to record my thoughts. In this sense, the blog is just like a diary.
- Blog is web based thus it is intended to be read by people. Blog can be a good communication tool to present the blogger. Blog is actually a bilateral communication tool because it allows other to comment.
Thursday, November 02, 2006
Monitor the Blog and Benchmark the Program
 I am using Google Analytics to monitor visits to my blog. See the picture, in which the dots indicates where somebody has visited my blog. There is even one returning visitor. Not bad!
I am using Google Analytics to monitor visits to my blog. See the picture, in which the dots indicates where somebody has visited my blog. There is even one returning visitor. Not bad!It is a good practice to start monitoring since the website is established. Just like it is a good practice to start benchmarking since the program is prototyped.
Monitoring is an inherent requirement of a website. Thus it should become a part of website infrastructure. I.e., when you establish a website, your website is automatically being monitored. No webmaster effort is involved.
Just like benchmarking is an inherent requirement of a program. Benchmarking should become a part of development environment. When you prototype a program, it costs you zero or little effort to benchmark the program. Some benchmark specific code should be automatically added into your program. Thus according to the benchmark data, you can make a decision on whether to take a certain refactoring or not. Will Aspect-Oriented Programming help on this?
Wednesday, November 01, 2006
Use VMware to Release Server-Side Software
I am using WMware's free VMware Server to create a GRIMOIRES virtual appliance. I admit it is not very easy to install GRIMOIRES. And I believe it is not easy to install any server-side software, probably because of the tedious and error prone procedure to configure, for instance, backend database, and security.
While VMware is able to relieve this pain. We create a VMware virtual appliance, which includes OS and our software. Our customer simply downloads it, and is able to play it, thus avoiding the painful installation procedure. The size of the VMware virtual appliance could be much much bigger than the size of our software. But who cares. Our computer spends more time in downloading, but we spend much less time in installation.
While VMware is able to relieve this pain. We create a VMware virtual appliance, which includes OS and our software. Our customer simply downloads it, and is able to play it, thus avoiding the painful installation procedure. The size of the VMware virtual appliance could be much much bigger than the size of our software. But who cares. Our computer spends more time in downloading, but we spend much less time in installation.
Tuesday, October 31, 2006
Massive Parallel Test Kit
I have implemented a Massive Parallel Test Kit (MPT) whose major goal is to measure the throughput of a server. While in my case, MPT is used to measure the throughput of our web service registry, GRIMOIRES.
MPT has the following features:
MPT has the following features:
- MPT is an MPI program. So it is able to create a large number of real parallel clients on a computer cluster to generate a large number of requests simultaneously. That is why it is claimed to be "massive parallel". By the way, it is really convenient to program a cluster using MPI.
- Each MPI process invokes a Java program, ThroughputTest. ThroughputTest provides basic functionalities required to run a throughput test. Above all, it supports user provided plug-in, called Worker, which implements the actual test business logic.
- In fact, Worker extends Thread. Thus two forms of parallelism are leveraged in MPT: multi-processing at the MPI level, and multi-threading in at the Java level.
- MPT has a single control point. The degree of multi-processing, the degree of multi-threading, and the test time are all set as the parameters for the MPI program. The latter two are then passed as environment variables to ThrouputTest.
- The fairness of the service can be revealed by calculating the deviation of the throughputs measured by individual MPI processes.
Monday, October 30, 2006

Many First Times Today

Happy today! Lovely weather. We had many first times today. For the first time, we had our Hong Kong style dim sum in UK. It is not bad. For the first time, we drove through a bridge asking for a payment, 50p. There is a good view along the bridge and nice drive.
Saturday, October 28, 2006

Subscribe to:
Posts (Atom)